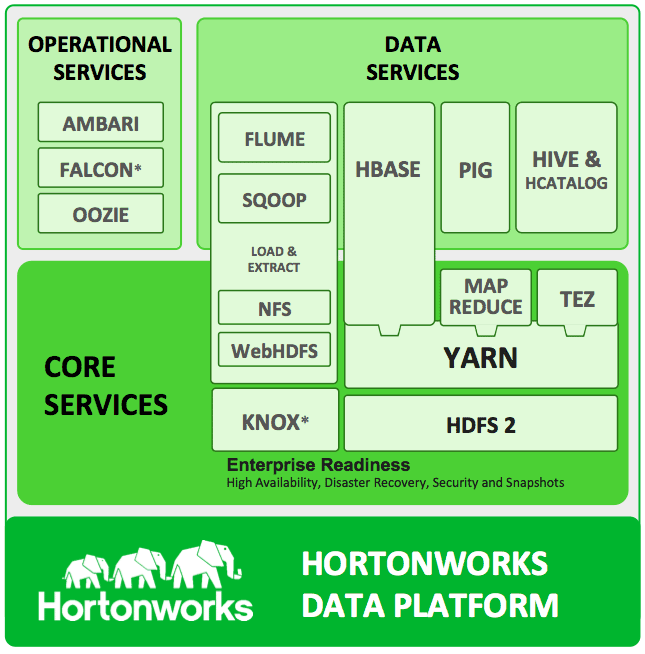
I have found it really helpful to have have a ready guide for the most commonly used command line commands for Hadoop. These are certainly there and available on every distribution of hadoop, but most new comers in this area struggle a lot. Here I have compiled a list of all the commands that a developer or a system admin may need to test, run and configure hadoop distributions. Please do note that even though most of these are generic, some distributions may add some modifications to it.
hadoop fs [-fs <local | file system URI>] [-conf <configuration file>]
[-D <property=value>] [-ls <path>] [-lsr <path>] [-du <path>]
[-dus <path>] [-mv <src> <dst>] [-cp <src> <dst>] [-rm [-skipTrash] <src>]
[-rmr [-skipTrash] <src>] [-put <localsrc> ... <dst>] [-copyFromLocal <localsrc> ... <dst>]
[-moveFromLocal <localsrc> ... <dst>] [-get [-ignoreCrc] [-crc] <src> <localdst>
[-getmerge <src> <localdst> [addnl]] [-cat <src>]
[-copyToLocal [-ignoreCrc] [-crc] <src> <localdst>] [-moveToLocal <src> <localdst>]
[-mkdir <path>] [-report] [-setrep [-R] [-w] <rep> <path/file>]
[-touchz <path>] [-test -[ezd] <path>] [-stat [format] <path>]
[-tail [-f] <path>] [-text <path>]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-chgrp [-R] GROUP PATH...]
[-count[-q] <path>]
[-help [cmd]]
-fs [local | <file system URI>]: Specify the file system to use.
If not specified, the current configuration is used,
taken from the following, in increasing precedence:
core-default.xml inside the hadoop jar file
core-site.xml in $HADOOP_CONF_DIR
'local' means use the local file system as your DFS.
<file system URI> specifies a particular file system to
contact. This argument is optional but if used must appear
appear first on the command line. Exactly one additional
argument must be specified.
-ls <path>: List the contents that match the specified file pattern. If
path is not specified, the contents of /user/<currentUser>
will be listed. Directory entries are of the form
dirName (full path) <dir>
and file entries are of the form
fileName(full path) <r n> size
where n is the number of replicas specified for the file
and size is the size of the file, in bytes.
-lsr <path>: Recursively list the contents that match the specified
file pattern. Behaves very similarly to hadoop fs -ls,
except that the data is shown for all the entries in the
subtree.
-du <path>: Show the amount of space, in bytes, used by the files that
match the specified file pattern. Equivalent to the unix
command "du -sb <path>/*" in case of a directory,
and to "du -b <path>" in case of a file.
The output is in the form
name(full path) size (in bytes)
-dus <path>: Show the amount of space, in bytes, used by the files that
match the specified file pattern. Equivalent to the unix
command "du -sb" The output is in the form
name(full path) size (in bytes)
-mv <src> <dst>: Move files that match the specified file pattern <src>
to a destination <dst>. When moving multiple files, the
destination must be a directory.
-cp <src> <dst>: Copy files that match the file pattern <src> to a
destination. When copying multiple files, the destination
must be a directory.
-rm [-skipTrash] <src>: Delete all files that match the specified file pattern.
Equivalent to the Unix command "rm <src>"
-skipTrash option bypasses trash, if enabled, and immediately
deletes <src>
-rmr [-skipTrash] <src>: Remove all directories which match the specified file
pattern. Equivalent to the Unix command "rm -rf <src>"
-skipTrash option bypasses trash, if enabled, and immediately
deletes <src>
-put <localsrc> ... <dst>: Copy files from the local file system
into fs.
-copyFromLocal <localsrc> ... <dst>: Identical to the -put command.
-moveFromLocal <localsrc> ... <dst>: Same as -put, except that the source is
deleted after it's copied.
-get [-ignoreCrc] [-crc] <src> <localdst>: Copy files that match the file pattern <src>
to the local name. <src> is kept. When copying mutiple,
files, the destination must be a directory.
-getmerge <src> <localdst>: Get all the files in the directories that
match the source file pattern and merge and sort them to only
one file on local fs. <src> is kept.
-cat <src>: Fetch all files that match the file pattern <src>
and display their content on stdout.
-copyToLocal [-ignoreCrc] [-crc] <src> <localdst>: Identical to the -get command.
-moveToLocal <src> <localdst>: Not implemented yet
-mkdir <path>: Create a directory in specified location.
-setrep [-R] [-w] <rep> <path/file>: Set the replication level of a file.
The -R flag requests a recursive change of replication level
for an entire tree.
-tail [-f] <file>: Show the last 1KB of the file.
The -f option shows apended data as the file grows.
-touchz <path>: Write a timestamp in yyyy-MM-dd HH:mm:ss format
in a file at <path>. An error is returned if the file exists with non-zero length
-test -[ezd] <path>: If file { exists, has zero length, is a directory
then return 0, else return 1.
-text <src>: Takes a source file and outputs the file in text format.
The allowed formats are zip and TextRecordInputStream.
[ Very Interesting: Can be used to display lines of a text file stored on HDFS]
-stat [format] <path>: Print statistics about the file/directory at <path>
in the specified format. Format accepts filesize in blocks (%b), filename (%n),
block size (%o), replication (%r), modification date (%y, %Y)
-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...
Changes permissions of a file.
This works similar to shell's chmod with a few exceptions.
-R modifies the files recursively. This is the only option
currently supported.
MODE Mode is same as mode used for chmod shell command.
Only letters recognized are 'rwxX'. E.g. a+r,g-w,+rwx,o=r
OCTALMODE Mode specifed in 3 digits. Unlike shell command,
this requires all three digits.
E.g. 754 is same as u=rwx,g=rx,o=r
If none of 'augo' is specified, 'a' is assumed and unlike
shell command, no umask is applied.
-chown [-R] [OWNER][:[GROUP]] PATH...
Changes owner and group of a file.
This is similar to shell's chown with a few exceptions.
-R modifies the files recursively. This is the only option
currently supported.
If only owner or group is specified then only owner or
group is modified.
The owner and group names may only cosists of digits, alphabet,
and any of '-_.@/' i.e. [-_.@/a-zA-Z0-9]. The names are case
sensitive.
WARNING: Avoid using '.' to separate user name and group though
Linux allows it. If user names have dots in them and you are
using local file system, you might see surprising results since
shell command 'chown' is used for local files.
-chgrp [-R] GROUP PATH...
This is equivalent to -chown ... :GROUP ...
-count[-q] <path>: Count the number of directories, files and bytes under the paths
that match the specified file pattern. The output columns are:
DIR_COUNT FILE_COUNT CONTENT_SIZE FILE_NAME or
QUOTA REMAINING_QUATA SPACE_QUOTA REMAINING_SPACE_QUOTA
DIR_COUNT FILE_COUNT CONTENT_SIZE FILE_NAME
-help [cmd]: Displays help for given command or all commands if none
is specified.